Generative AI has become the disruptor in all sectors, driving progress in natural language processing, computer vision, and many other areas. However, using its potential has often been accompanied by challenges of costs, complex infrastructure, and steep learning curves. That’s where AWS Bedrock comes in – this solution helps unblock by allowing you to use foundation models without the need to manage infrastructure.
This tutorial aims to be your complete guide to Amazon Bedrock, describing what it is, how it works, and how you can use it. By the end of this guide, you’ll have the information and skills you need to develop your own generative AI applications—scalable, flexible, and aligned to your goals.
For instance, imagine you are developing a customer support chatbot. With AWS Bedrock, you can select a sophisticated language model, tune it for your application’s needs, and embed it in your application without ever having to write server configuration in code.
AWS Bedrock’s features are designed to simplify and accelerate the journey from AI concept to production. Let’s break them down in detail.
One of the most significant benefits of AWS Bedrock is the variety of foundation models available. Whether you are working on text applications, visual content, or safe and interpretable AI, Bedrock has you covered. Here are some of the models available:
Amazon models: These proprietary models can be used for tasks like creating human-like text for chatbots or content creation applications, reducing the length of documents to their essence, or interpreting the sentiment of customer feedback.
Anthropic models: These models focus on developing good, safe artificial intelligence and are most suitable for industries that require compliance and trust, such as banking or healthcare.
Stability AI: Stability AI models are well known for their image generation. They help transform ideas into visuals for marketing, artwork, or product development.
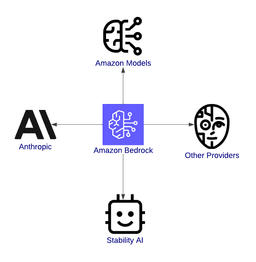
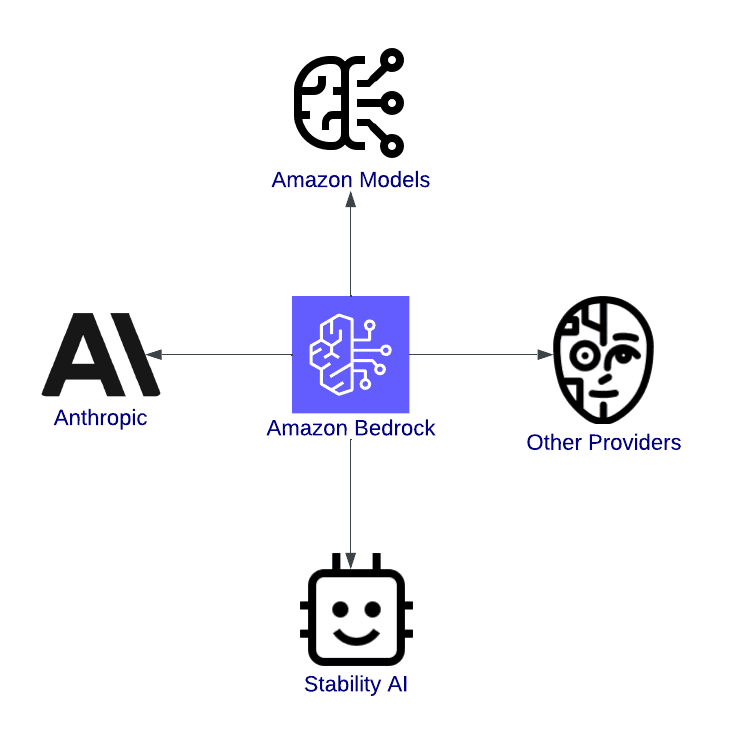 Diagram of Amazon Bedrock, connecting to Amazon Models, Anthropic, Stability AI, and other providers, illustrating its role as a hub for generative AI services.
Diagram of Amazon Bedrock, connecting to Amazon Models, Anthropic, Stability AI, and other providers, illustrating its role as a hub for generative AI services.Overview of Amazon Bedrock, highlighting its integration with models.
AWS Bedrock abstracts infrastructure management, which means:
No need to provision GPU instances.
You can focus purely on building applications with a serverless architecture.
The ease of use reduces setup times significantly, often from weeks to hours.
AI generative applications typically have an unpredictable demand. A chatbot may respond to hundreds of users during peak hours and only a few at night. But AWS Bedrock solves this with its built-in scalability:
Automatic scaling: This means models can automatically adjust to handle workload spikes without you having to intervene manually.
Parallel workloads: You can run multiple models at once for different use cases within a single application.
Global availability: With AWS’s global network, you can deploy your applications closer to your users, cutting latency and enhancing user experience.
AWS Bedrock goes beyond providing powerful models—it integrates with other AWS services to support end-to-end AI workflows. Some integrations include:
Amazon SageMaker: Enables fine-tuning of foundation models to meet specific requirements.
AWS Lambda: Facilitates event-driven AI applications, such as triggering a model to fine-tune new data or review inference results.
Amazon CloudWatch: Provides monitoring and logging capabilities for analyzing model performance and gathering user feedback.
Amazon S3: Serves as a storage solution for datasets, enabling performance tracking and cost analysis.
Learn to optimize AWS services for cost efficiency and performance.
This section will guide you through setting up the necessary permissions, creating an AWS account, and getting started with AWS Bedrock.
 AWS sign-up page with a form to input a root user email address and AWS account name.
AWS sign-up page with a form to input a root user email address and AWS account name.The AWS sign-up page, showcasing Free Tier product exploration for new accounts.
Amazon Bedrock is accessible through the AWS Management Console. Follow these steps to locate and start using it:
Search for Bedrock: Use the search bar at the top of the console. Type “Bedrock” and select it from the dropdown.
 Screenshot of AWS Management Console search results for "Bedrock," displaying Amazon Bedrock as the service for building generative AI applications, Amazon SageMaker for data and AI analytics, and a highlighted introduction to resource search with cross-region capabilities
Screenshot of AWS Management Console search results for "Bedrock," displaying Amazon Bedrock as the service for building generative AI applications, Amazon SageMaker for data and AI analytics, and a highlighted introduction to resource search with cross-region capabilitiesAWS Management Console search results for Bedrock.
 Screenshot of the Amazon Bedrock Providers page featuring three serverless model providers: Amazon, Anthropic, and Meta
Screenshot of the Amazon Bedrock Providers page featuring three serverless model providers: Amazon, Anthropic, and MetaAmazon Bedrock Providers page showcasing serverless model options from Amazon.
Select a model provider and a foundation model:
Choose a provider based on your use case (e.g., Amazon Titan for text generation, Stability AI for images, etc.).
Explore model-specific options like input types, supported features, and output parameters.
Run a test inference: AWS Bedrock allows you to run sample inferences directly from the console. This is a great way to get a feel for how each model works before integrating it into your application.
 Screenshot of the Amazon Bedrock Chat/Text Playground, featuring the Claude 3 Opus model. The interface includes options to input a prompt, run responses, and compare different models. The left panel lists options like "Getting started," "Foundation models," "Playgrounds," "Builder tools," and "Safeguards."
Screenshot of the Amazon Bedrock Chat/Text Playground, featuring the Claude 3 Opus model. The interface includes options to input a prompt, run responses, and compare different models. The left panel lists options like "Getting started," "Foundation models," "Playgrounds," "Builder tools," and "Safeguards."Amazon Bedrock Chat/Text Playground interface.
AWS Identity and Access Management (IAM) is critical for securely accessing AWS Bedrock. Follow these steps to configure permissions:
In the AWS Management Console, navigate to the IAM service.
Click Roles in the sidebar and select Create policy.
In Specify permissions, choose “JSON”.
 Screenshot of the AWS IAM Policy Editor in JSON mode, showing a partially configured policy with an empty "Action" and "Resource" list. The left sidebar indicates a two-step process: "Specify permissions" and "Review and create." The right panel provides options to add actions, filter services, and remove statements.
Screenshot of the AWS IAM Policy Editor in JSON mode, showing a partially configured policy with an empty "Action" and "Resource" list. The left sidebar indicates a two-step process: "Specify permissions" and "Review and create." The right panel provides options to add actions, filter services, and remove statements.AWS IAM Policy Editor in JSON mode
{
"Version": "2012-10-17",
"Statement": [ {\
"Sid": "BedrockFullAccess",\
"Effect": "Allow",\
"Action": ["bedrock:*"],\
"Resource": "*"\
}\
]
}
Powered By
Was this AI assistant helpful? Yes No
Note: The policy above can be attached to any role that needs to access the Amazon Bedrock service. It can be SageMaker or a user. When using Amazon SageMaker, the execution role for your notebook is typically a different user or role than the one you use to log in to the AWS Management Console. To find out how to explore Amazon Bedrock service using the AWS Console, ensure you authorize your Console user or role. You can run the notebooks from any environment with access to the AWS Bedrock service and valid credentials.
Generative AI applications are built upon foundation models that are fine-tuned for a particular task, such as text generation, image creation, or data transformation. Following is a step-by-step guide on choosing a foundation model, using basic inference jobs, and modifying model responses to suit your needs.
Picking the right foundation model is important because it depends on what your project needs. Here’s how to make a selection:
Text generation: For tasks like summarization, content creation, or chatbot development, consider models like:
Amazon Titan Text G1: This model generates high-quality text with a good understanding of the context.
Anthropic Claude 3: This model is very good at producing text that is coherent and relevant to the context and is thus suitable for conversational AI applications.
Image generation: If your project is about creating images or any form of visual content, then Stability AI models are the way to go:
Multimodal tasks: For applications that need both text and image processing, Amazon Nova models are recommended:
Nova Lite: A cost-sensitive multimodal model that can take text, image, and video input and output text.
Nova Pro: A competent multimodal model for more complex tasks.
Before using these models, you need to enable model access within your AWS account. Here are the steps to set it up:
In the Bedrock Console, navigate to Models access.
In the Console, click on Modify model access.
Browse the available models from providers and select the one you like. In this case, I selected Titan Text G1—Express.
 Screenshot of the Amazon Bedrock "Edit model access" page, showing a list of Amazon Titan models with their access statuses. Some models have "Access granted," while others are "Available to request." The interface includes options to filter models, expand or collapse sections, and group models by provider. The left panel shows a two-step process: "Edit model access" and "Review and submit."
Screenshot of the Amazon Bedrock "Edit model access" page, showing a list of Amazon Titan models with their access statuses. Some models have "Access granted," while others are "Available to request." The interface includes options to filter models, expand or collapse sections, and group models by provider. The left panel shows a two-step process: "Edit model access" and "Review and submit."Amazon Bedrock model access management page.
To perform inference using a selected foundation model in AWS Bedrock, follow these steps:
pip install boto3
Powered By
Was this AI assistant helpful? Yes No
python
import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)
Powered By
Was this AI assistant helpful? Yes No
python
# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""
Powered By
Was this AI assistant helpful? Yes No
python
# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)
Powered By
Was this AI assistant helpful? Yes No
python
try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:
", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")
Powered By
Was this AI assistant helpful? Yes No
You can expect the below output:
bash
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service Manager
Powered By
Was this AI assistant helpful? Yes No
temperature and maxTokenCount:temperature: This parameter controls the randomness of the output. Lower values increase the determination of the output, and higher values increase the variability.MaxTokenCount: Sets the maximum length of the generated output.For example:
python
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}
Powered By
Was this AI assistant helpful? Yes No
By adjusting these parameters, you can better tailor the creativity and length of the generated content to your application's needs.
Learn to optimize AWS services for cost efficiency and performance.
Let’s switch gears and focus on two advanced approaches: enhancing AI using Retrieval-Augmented Generation (RAG) and managing and deploying models at scale.
RAG requires us to have a knowledge base. Before setting up the knowledge base in Amazon Bedrock, you need to create an S3 bucket and upload the required files. Follow these steps:
Log in to the AWS Management Console:
Create a new bucket:
Click Create bucket.
Enter a unique bucket name.
Leave default settings unless you have specific security or encryption requirements.
Configure the bucket settings:
Ensure that block public access is enabled unless you require it.
(Optional) Enable versioning if you want to maintain versions of your files.
Create the bucket:
Step 2: Upload files to the S3 bucket
Download the file:
Save it locally on your computer.
Upload the file to S3:
Open the newly created S3 bucket in the AWS Console.
octank_financial_10K.pdf.Review and set the permissions (default: private).
Click Upload to add the file to the bucket.
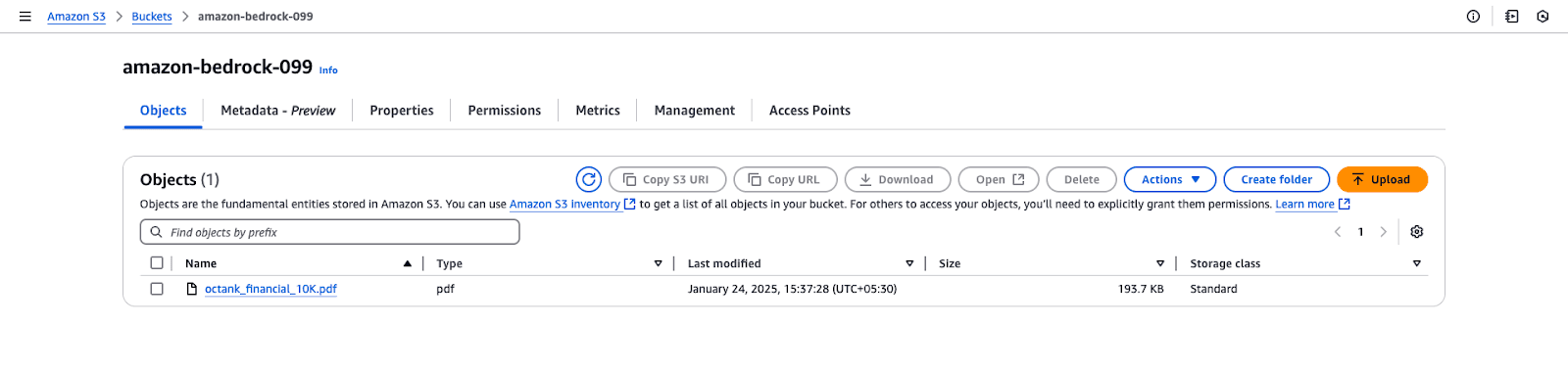 Screenshot of an Amazon S3 bucket named "amazon-bedrock-099," displaying the "Objects" tab with a single PDF file named "octank_financial_10K.pdf."
Screenshot of an Amazon S3 bucket named "amazon-bedrock-099," displaying the "Objects" tab with a single PDF file named "octank_financial_10K.pdf."Amazon S3 bucket view for "amazon-bedrock-099".
Navigate to the Amazon Bedrock Console and select Knowledge Bases under the Builder tools section.
Click Create Knowledge Base and fill out the following details:
knowledge-base-quick-start).Knowledge Base description: (Optional) Briefly describe the knowledge base.
In the IAM permissions section:
Choose “Create and use a new service role” or “Use an existing service role”.
Ensure the service role has the necessary permissions for Bedrock access.
AmazonBedrockExecutionRoleForKnowledgeBase.Click Next to proceed with configuring the data source.
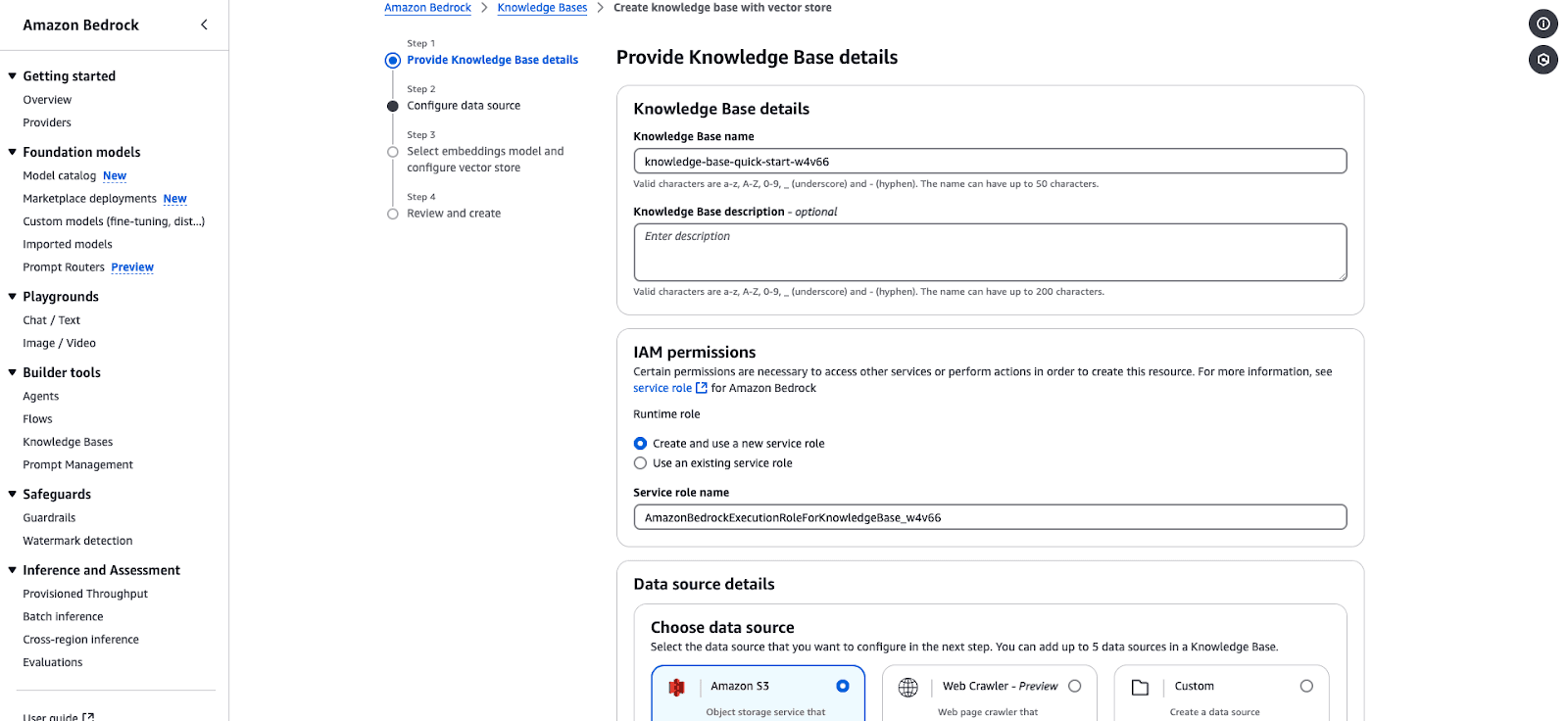 Screenshot of the Amazon Bedrock Knowledge Base creation interface, showing steps to configure a knowledge base.
Screenshot of the Amazon Bedrock Knowledge Base creation interface, showing steps to configure a knowledge base.Amazon Bedrock Knowledge Base creation wizard.
Under the Data source details section, choose your data source:
Specify the following:
Data source location: Choose between "This AWS Account" or "Other AWS Account."
S3 URI: Provide the S3 bucket URI containing the data. Choose the S3 you created in the previous step and the file.
Encryption key: (Optional) Add a customer-managed KMS key if your data is encrypted.
Configure the parsing strategy:
Default parser: Processes plain text data. You can leave it as is.
Foundation models as parser: Processes complex documents or images. You can leave it as is.
Chunking strategy:
(Optional) Add Transformation functions or advanced settings to preprocess your data. You can leave it as is.
Click Next to proceed.
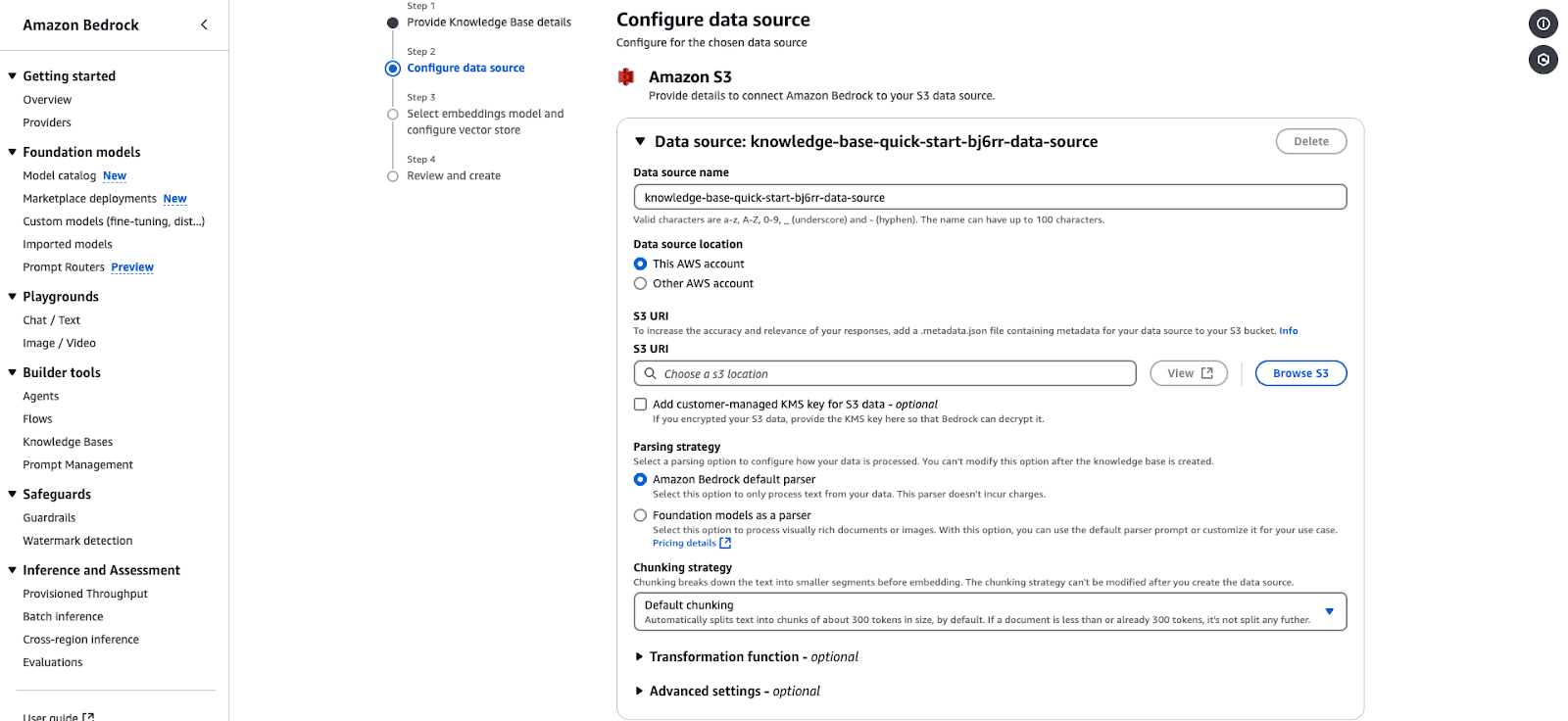 Screenshot of the Amazon Bedrock data source configuration interface, showing settings for connecting an Amazon S3 data source
Screenshot of the Amazon Bedrock data source configuration interface, showing settings for connecting an Amazon S3 data sourceAmazon Bedrock data source configuration page for integrating an S3-based knowledge base.
Choose an Embeddings model to convert your data into vector representations:
Text v1.2 (You can choose this for this tutorial.)
Embed English v3
Embed Multilingual v3
Under the Vector database section:
Choose “Quick create a new vector store” (recommended) or select an existing store.
Options include:
Amazon OpenSearch Serverless: This is ideal for contextually relevant responses. You can choose it for the purpose of this tutorial.
Amazon Aurora PostgreSQL Serverless: Optimized for fast similarity searches.
Amazon Neptune Analytics: Suitable for graph-based analytics and Retrieval-Augmented Generation (RAG).
Click Next to review and finalize your configuration.
 Screenshot of the Amazon Bedrock interface for selecting an embeddings model and configuring a vector database.
Screenshot of the Amazon Bedrock interface for selecting an embeddings model and configuring a vector database.Amazon Bedrock configuration page for selecting an embedding model and vector store.
Review all your configurations.
Confirm and click Create to finalize the knowledge base.
Once created, your knowledge base will appear under the Knowledge Bases section in the console.
Access the knowledge base overview:
Go to the Knowledge Bases section in the Amazon Bedrock Console.
knowledge-base-quick-start).Review the overview details:
Knowledge Base name and ID
Ensure it is set to “Available”.
Verify the correct service role is in use.
Sync and add data sources:
If the data source hasn’t been synced, click Sync to initiate the process.
You can also add more documents or data sources via Add documents from S
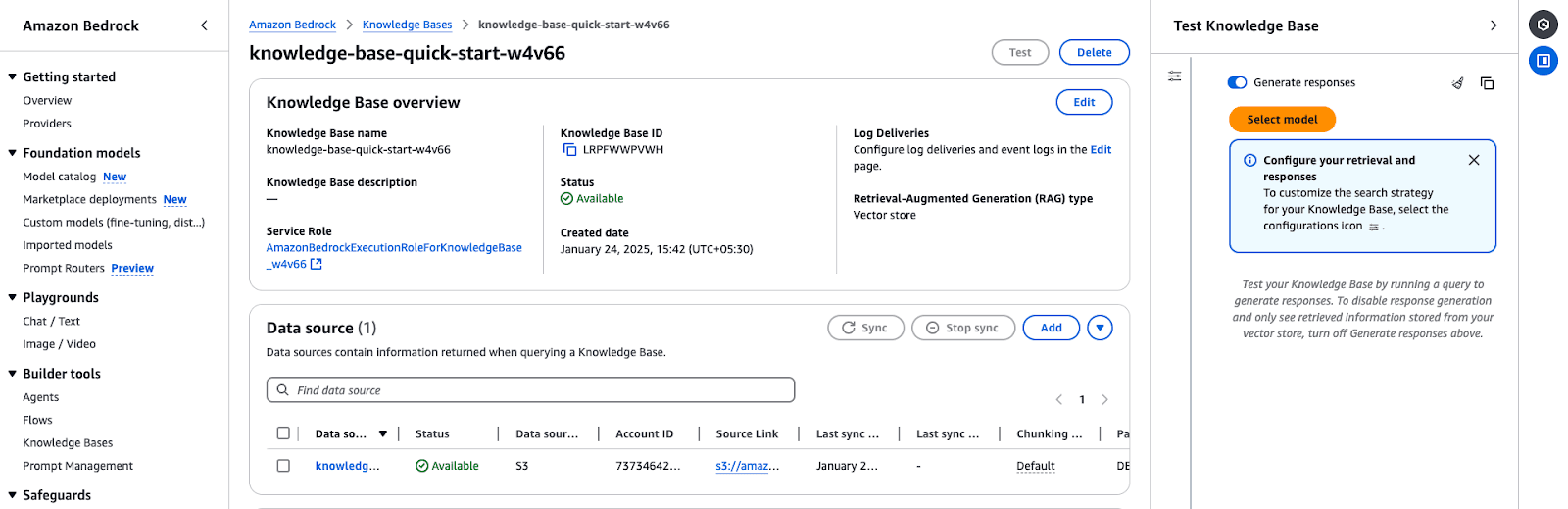 Screenshot of the Amazon Bedrock Knowledge Base overview page, displaying key details such as the knowledge base name, ID, service role, status, and retrieval-augmented generation (RAG) type.
Screenshot of the Amazon Bedrock Knowledge Base overview page, displaying key details such as the knowledge base name, ID, service role, status, and retrieval-augmented generation (RAG) type.Amazon Bedrock Knowledge Base overview shows configuration details and data source status.
Choose a foundation model:
Click Select model in the Test Knowledge Base panel.
Browse the available models from providers like Amazon, Anthropic, and Cohere.
Example: Select Claude Instant (v1.2) for text-based queries.
Inference type:
Apply the model:
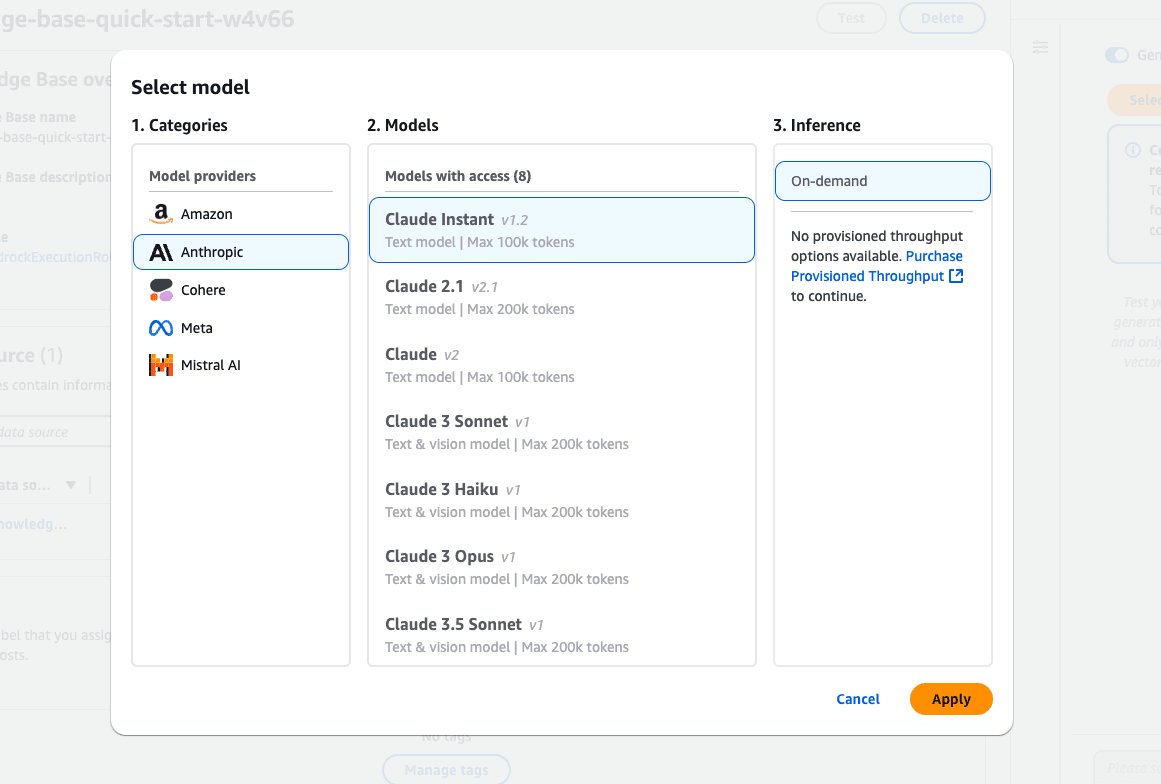 Screenshot of the Amazon Bedrock "Select model" interface, displaying model providers including Amazon, Anthropic, Cohere, Meta, and Mistral AI.
Screenshot of the Amazon Bedrock "Select model" interface, displaying model providers including Amazon, Anthropic, Cohere, Meta, and Mistral AI.Amazon Bedrock model selection interface features various Claude models from Anthropic.
Generate a response:
Enter your query in the input box (e.g., “Help me with Financial Statement Schedules”).
Click Run to test the knowledge base.
View source details:
The response will include chunks of data relevant to your query.
Expand Source Details to view metadata and the source of the retrieved information.
Review the output:
Validate the response to ensure it aligns with the knowledge base content.
Fine-tune retrieval configurations if necessary.
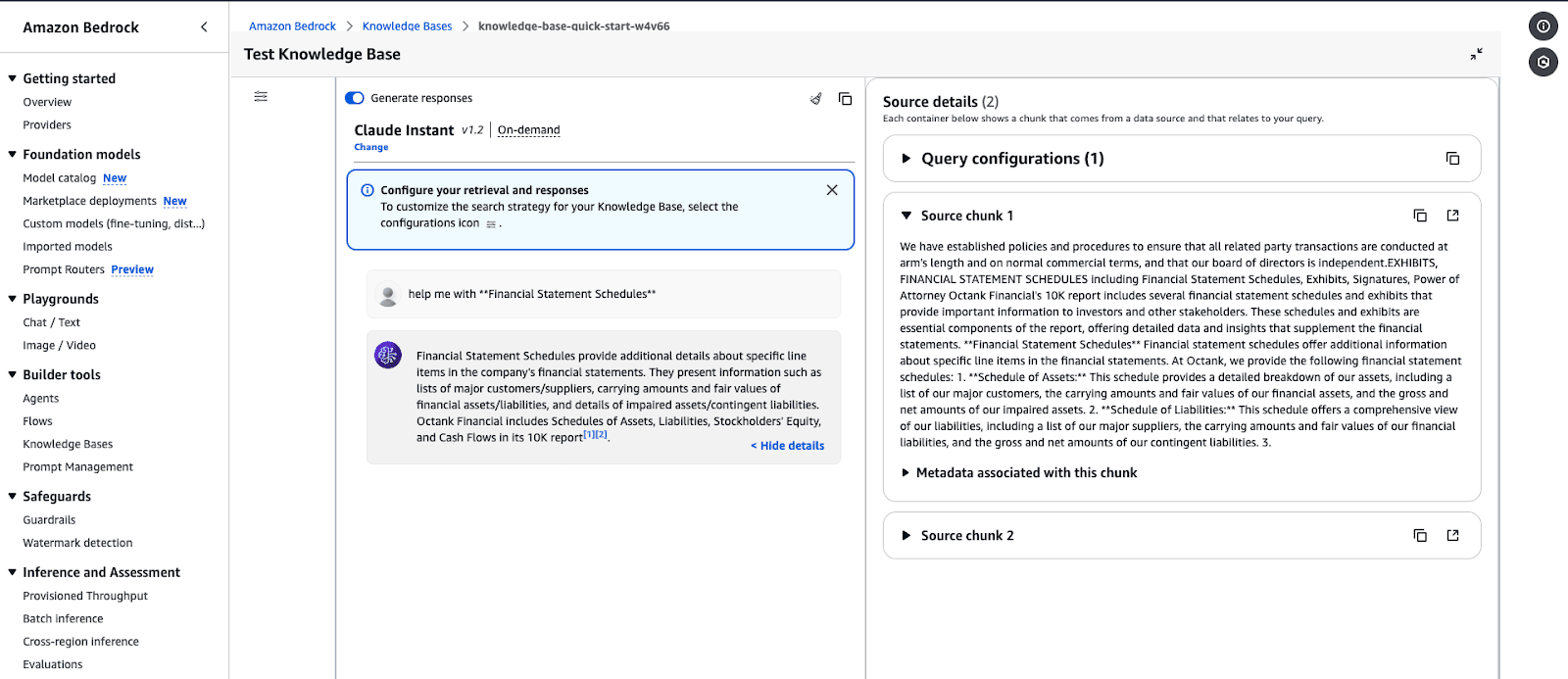 Screenshot of the Amazon Bedrock Knowledge Base testing page. The selected model is "Claude Instant v1.2" set to on-demand inference.
Screenshot of the Amazon Bedrock Knowledge Base testing page. The selected model is "Claude Instant v1.2" set to on-demand inference.Amazon Bedrock Knowledge Base testing interface displaying a response for a query.
Example query output:
Using AWS services like Lambda, Amazon Bedrock can manage and deploy AI models at scale. This cost-efficient approach ensures high availability and automatically scales for AI-powered applications.
In this section, we will use AWS Lambda to invoke a Bedrock model dynamically so you can process prompts on demand.
Log in to the AWS Management Console.
Navigate to the Lambda service and click Create function.
Choose the function configuration:
Select “Author from Scratch”.
Function name: bedrock.
Runtime: Python 3.x.
Permissions: Select an IAM Role that has been created in the initial section of this tutorial.
Click Create function to initialize the setup.
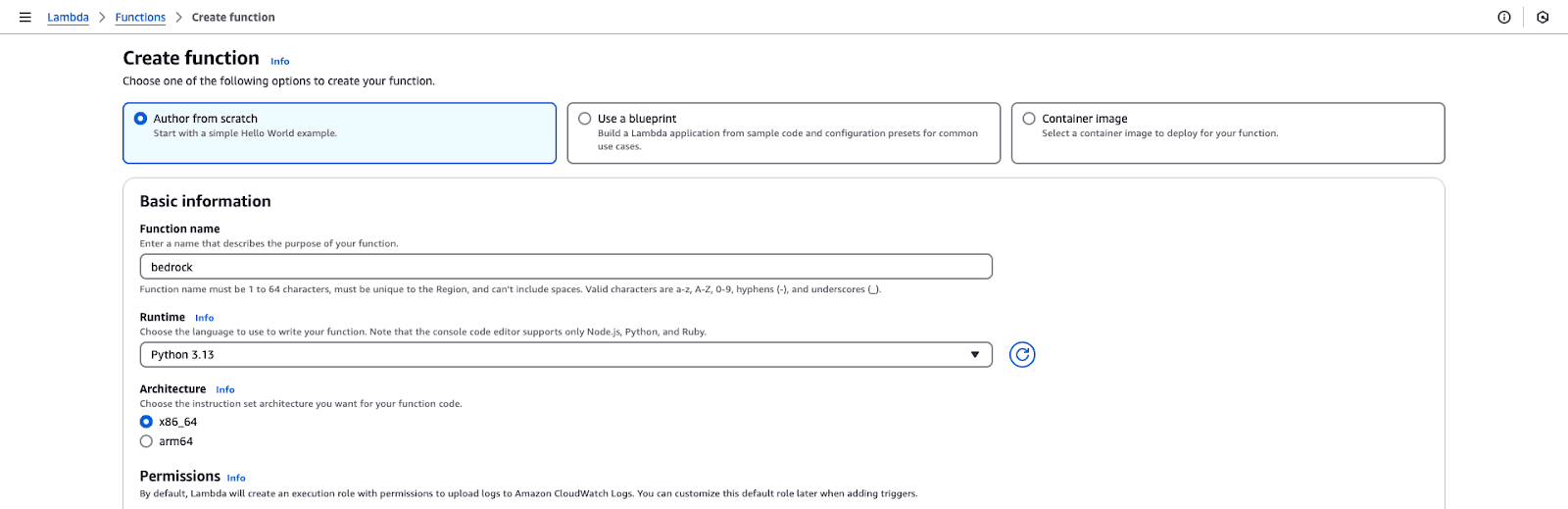 Screenshot of the AWS Lambda function creation interface. The selected option is "Author from scratch," and the function name is set to "bedrock."
Screenshot of the AWS Lambda function creation interface. The selected option is "Author from scratch," and the function name is set to "bedrock."AWS Lambda function creation page.
Open the function editor in the Code section of the Lambda console.
Click Deploy to save the changes.
none
{
"prompt": "Write a formal apology letter for a late delivery."
}
Powered By
Was this AI assistant helpful? Yes No
Save the test event.
Click Test to invoke the Lambda function.
Check the output in the Execution results section. The generated text should look like this:
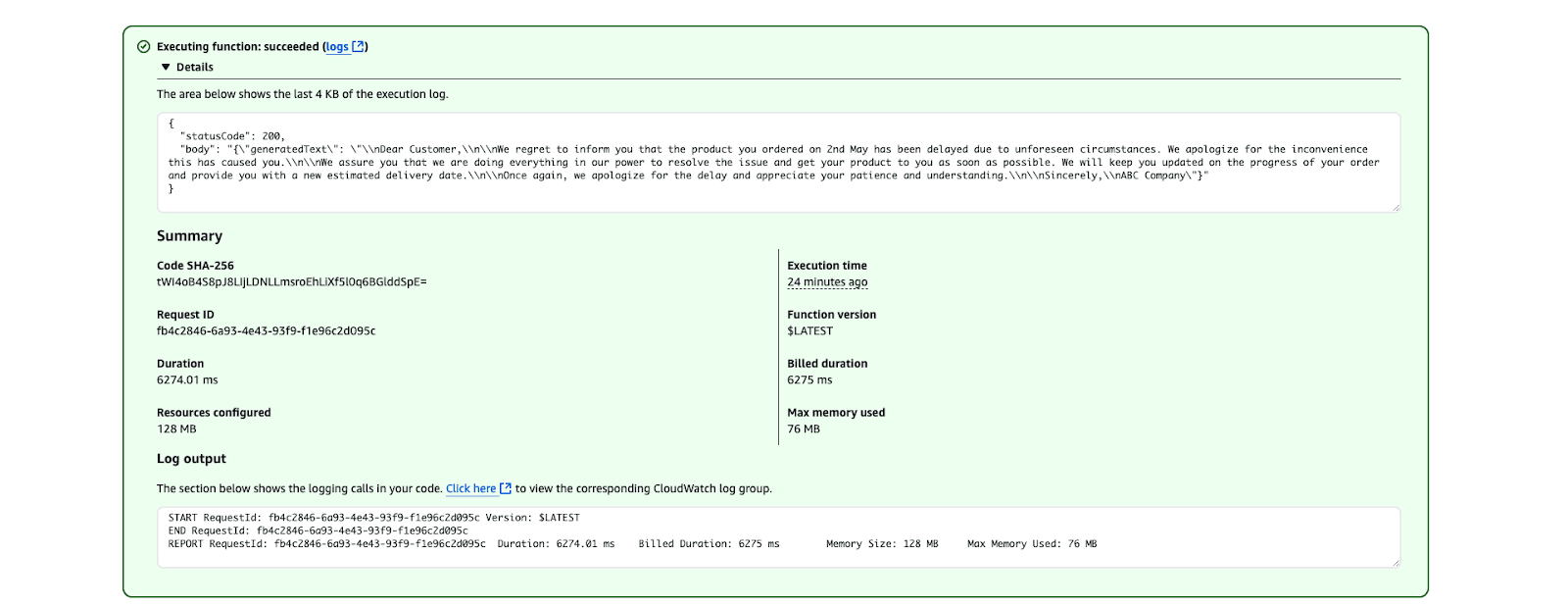 Screenshot of AWS Lambda execution results indicating a successful function execution
Screenshot of AWS Lambda execution results indicating a successful function executionAWS Lambda execution result showing a successful function run.
Optimize cost:
Use on-demand inference for occasional use cases.
Consider provisioned throughput if high-frequency requests are expected.
Secure the Lambda function:
Restrict the IAM role to only the required permissions.
Use environment variables to avoid exposing sensitive data in code.
Monitor and log:
Use CloudWatch logs to track invocation metrics and debug issues.
Set up alarms for errors or high latency.
In this section, I share some best practices when working with Amazon Bedrock, from optimizing costs to keeping things secure and accurate.
Managing costs in AWS Bedrock may involve leveraging Amazon SageMaker to deploy models and utilize Spot instances to save up to 90% on expenses. Here are some of my best practices:
Choose the right foundation model: Select models that align with your needs. Choose smaller, less resource-intensive models to reduce compute costs for less complex tasks. For example, Amazon Titan Models can be used for text-based tasks like summarization or Stability AI for simple image generation.
Batch inference: Instead of processing requests individually, group multiple inference requests into batches. This reduces the frequency of model invocations, leading to lower costs.
Leverage S3 lifecycle policies: Store only the data you need for inference or fine-tuning in Amazon S
 Graph depicting the cost and usage of Amazon Bedrock services
Graph depicting the cost and usage of Amazon Bedrock servicesCost and usage graph for Amazon Bedrock services.
Use Bedrock with SageMaker for cost efficiency: Use Bedrock foundation models in SageMaker to take advantage of managed Spot instances for inference and training jobs.
python
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
Powered By
Was this AI assistant helpful? Yes No
 Screenshot of AWS CloudWatch log events, displaying entries for a machine learning model under the path /opt/ml/model. Each log includes a timestamp, source IP, and HTTP GET request to /ping with a 200 status code.
Screenshot of AWS CloudWatch log events, displaying entries for a machine learning model under the path /opt/ml/model. Each log includes a timestamp, source IP, and HTTP GET request to /ping with a 200 status code.AWS CloudWatch logs
To ensure the security, compliance, and performance of Amazon Bedrock, it is important to follow the best practices. Here are my recommendations:
Apply least privilege access: Restrict IAM permissions and service roles to only the necessary resources to prevent unauthorized access.
Validate service roles and security groups: Ensure Bedrock agents and model customization jobs are correctly configured with active service roles and security settings.
Implement data deletion policies: Retain vector-stored data only when knowledge-based sources are active; set up automatic deletion when no longer needed.
Strengthen Bedrock guardrails: Set Prompt Attack Strength to HIGH and enable sensitive information filters to protect against adversarial attacks and data leaks.
Secure agent sessions: Use guardrails to prevent unauthorized access and protect sensitive interactions.
Enable logging for visibility: Turn on model invocation logging at the account level to track activity and detect anomalies.
Defend against cross-service attacks: Use service role policies to prevent Cross-Service Confused Deputy Attacks.
Ensuring that models are accurate, reliable, and aligned with business objectives is achieved by monitoring and evaluating models. Here are some best practices:
Track performance metrics: Use CloudWatch to monitor latency, errors, and invocation trends.
Log inputs and outputs: Enable detailed logging for debugging and trend analysis.
Incorporate feedback loops: Use tools like Amazon A2I to include human reviews for critical outputs.
Evaluate outputs regularly: Compare outputs with validation datasets or ground truth.
Continuously improve models: Fine-tune models with updated datasets or specific domain data as needed.
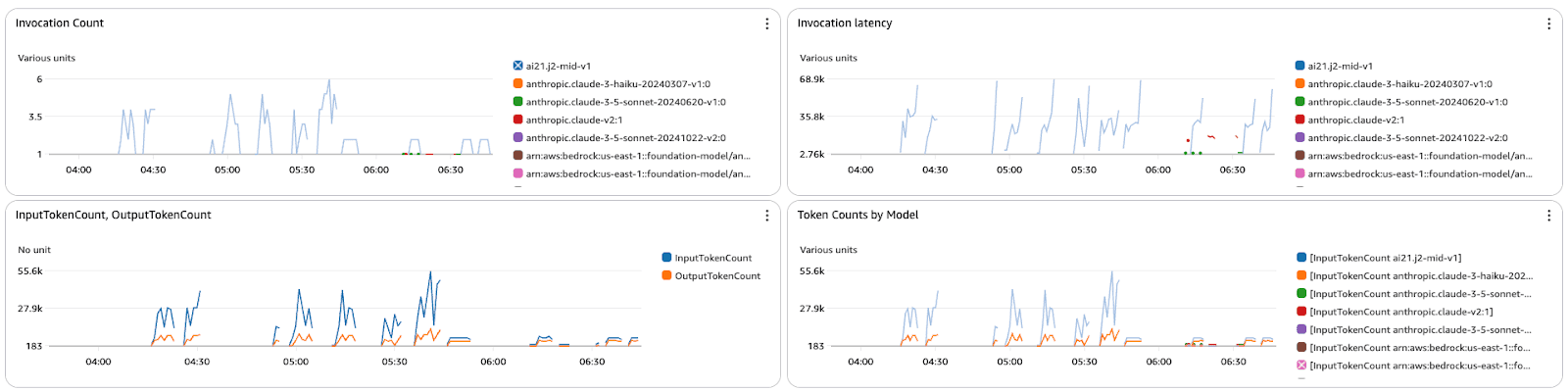 Dashboard with four graphs tracking metrics for Amazon Bedrock models.
Dashboard with four graphs tracking metrics for Amazon Bedrock models.The metrics dashboard displays the invocation count, latency, and token counts for various models in Amazon Bedrock.
AWS Bedrock is a game-changer in how generative AI applications are developed and a centralized platform for using foundation models without worrying about the infrastructure.
From this point forward, this step-by-step tutorial should help you identify the right models, create secure and scalable workflows, and integrate features like retrieval-augmented generation (RAG) for greater customization. With the best practices for cost, security, and monitoring in place, you are ready to develop and manage your AI solutions to meet your objectives.
To further deepen your AWS expertise, explore these courses:
Learn to build AI applications using the OpenAI API.
Business, governance, and adoption-focused material. Real-world implementations, case studies, and industry impact.